低空复杂场景红外弱小目标快速精准检测*
周 海,李保权,王怀超,卞春江
(1. 中国科学院国家空间科学中心 复杂航天系统电子信息技术重点实验室, 北京 100190;
2. 中国科学院大学, 北京 100049;
3. 中国民航大学 计算机学院, 天津 300300)
基于红外传感器的低空运动小目标探测因具有隐蔽性高、覆盖范围广和全天候工作的特点,在现代国防、红外监视和空中交通管制等军民领域均发挥着重要作用[1-3]。真实低空场景下,红外小目标检测依然受到诸多挑战:①由于观测距离远,无人机、飞机模型、风筝等低空目标往往很小很弱,形状和纹理信息不明显;
②由于低空观测环境复杂,背景中可能含有树木、植被、地物等强干扰[4](如图1所示),这些干扰源进一步加大了小目标检测难度;
③红外传感器在探测跟踪系统中主要定位于目标发现,在处理中需以极低的时延生成检测信息用于对系统内其他单元进行引导,检测性能与处理实时性是决定系统整体性能的关键性设计。

(a) 低空复杂场景代表性目标(a) Low-altitude complex scenes representative targets

(b) 低空复杂场景能量三维图示(b) Low-altitude complex scenes energy 3D diagram图1 低空复杂场景代表性目标及相应的能量三维图示Fig.1 Representative targets in low-altitude complex scenes and corresponding energy 3D diagram
近20年来,随着红外探测器的快速发展与应用,出现了大量针对各种场景的红外小目标检测方法。这些方法主要分为两类:基于单帧的检测方法和基于序列的检测方法。基于单帧的检测方法通常利用图像空间域的局部差异[5]设计不同的滤波器来抑制噪声和杂波,如top-hat变换[6]、最大中值和最大均值滤波器[7]等。文献[8]基于人类视觉注意机制提出了局部对比度量(local contrast measure, LCM)方法。在此方法基础上,产生了许多改进的LCM方法[9],如多尺度相对局部对比度量(relative local contrast measure, RLCM)[10]和基于多尺度面片的对比度量(multiscale patch-based contrast measure, MPCM)[11]等。对于简单场景,这些方法可以有效抑制杂波并增强目标,但对于低空复杂场景,由于存在大量与目标相似的干扰导致检测虚警率较高。基于序列的检测方法利用时域相关性对图像背景进行估计,并利用空域信息对目标进行检测。时空局部对比度滤波器(spatial-temporal local contrast filter, STLCF)使用空间局部对比度和时间局部对比度来增强目标[12]。此外,许多方法使用稀疏表示来分离连续图像上的背景和目标[4]。时间滤波和关联策略(temporal filtering and association strategy, TFAS)方法利用最大滤波和中值滤波的时间融合(max filter and median filter temporal fusion, MMTF)来检测目标,然后执行关联操作以形成连续的轨迹[13]。与基于单帧的检测方法相比,基于序列的检测方法使用了额外的图像时间维度信息,其检测精度更高。
近些年,深度学习方法飞速发展,在通用目标检测领域产生了革命性的进步,针对具有丰富纹理特征的大尺度目标,产生了很多深度检测网络,如FasterRCNN[14]、YOLO[15]、SSD[16]等。但是,针对低空红外弱小目标,由于缺乏显著的纹理和形状信息,这些网络检测性能并不理想。
针对低空复杂场景下红外弱小动目标检测率和虚警率方面的不足,本文在传统方法基础上引入全卷积网络(fully convolutional network, FCN)进行性能提升。
本文算法充分利用时空域信息实现弱小目标高精度检测,整体流程如图2所示。对于每一帧图像首先采用全卷积网络得到目标检测概率分布热图,并在阈值分割后通过空域连通将杂散疑似目标连通标记成备选关联目标。由于目标检测概率分布热图中存在的虚警一般由噪声、地上固定物或盲元产生,通常不具备规则的运动信息,故可以将相邻两帧备选关联目标进行轨迹关联,进一步消除虚警,得到鲁棒的检测结果。

图2 本文算法流程Fig.2 Framework diagram of the proposed method
1.1 全卷积网络
红外弱小目标由于没有显著的轮廓和形状信息,很难直接应用当前的深度检测网络。低空弱小目标在远距离情况下会退化成尺度非常小的目标,因而需要预测一幅图像中所有像素点的类别,是个像素密集型检测任务。全卷积网络[17]能够对图像进行像素级的分割,其网络结构设计思想非常适用于红外弱小目标检测任务。同时该网络具有以下几方面优势:①输入图像可以是任意尺寸, 因而图像处理时不需要特定步骤对其进行尺寸预处理,并且当需要对图像分块以满足并行流水化处理要求时,可对图像进行任意大小的块分割,便于匹配并行处理架构计算需求;
②对目标的分割分类属于像素级的分类方法, 并且具备尺度和旋转不变性;
③每个像素对应位置像素点的端对端训练方式比利用图像上下文信息和局部特征训练参数更加高效。
但传统全卷积网络是针对通用实例分割任务设计,通常分割的目标较大,所以不加改进直接应用于红外弱小目标检测会影响检测性能。为提高网络的红外弱小目标检测精度, 权衡硬件实现成本,本小节对全卷积网络结构进行了优化, 构建了一种适合红外弱小目标空域检测的全卷积回归网络。
1)减少网络层数:卷积神经网络原理上是通过更深的网络层数来学习更抽象的特征表示,这样可以有效增加通用场景的目标检测精度。但对于低空红外图像,由于图像噪声强度大,小目标形状和纹理特征非常弱,所以较深的网络层数很难学习到有效的抽象特征表示,进而影响检测精度。对传统全卷积网络的16个卷积层进行削减,一方面保持对小目标底层特征的充分利用,另一方面随层数降低可以有效减小模型参数,降低计算量。经过多次实验,当网络层数逐步减少至5时,网络精度变化小于0.3%;
当网络层数减少至4时,精度下降明显。权衡精度与计算量,算法采用5层卷积层构建检测网络。
2)降低池化层影响:池化层步长越大,则该层之后的其他各层存储计算资源消耗越小,但过大的步长也会损失图像细节特征。为了确保网络检测精度并得到稠密的检测结果,经多次实验,仅在将第一个池化层的步长设置为2、其余池化层的步长均设置为1的情况下,可以在不影响检测精度的前提下降低部分硬件资源消耗。
3)使用回归头:传统全卷积网络输出层经过softmax函数得到分类结果,而对于小目标检测,如果将其最终结果简单看成是二分类问题,那么正负样本会严重失衡,且不能得到小目标的精确位置。因此输出层使用均方误差回归损失函数替代softmax函数,可以得到当前像素点x是目标的概率p(t|NX,xij∈NX),其中NX表示像素点x的邻域。
4)优化归一化(batch normalization, BN)层位置:归一化层主要用于网络训练过程中加快训练收敛,避免梯度消失和过拟合。传统全卷积网络中归一化层通常放在激活层后面,但归一化层仅作用于网络训练阶段,对于网络推理阶段其参数已经固定,适合与卷积层通过融合处理的方式降低计算量。将其调整至卷积层与激活层中间,加速网络训练的同时又充分考虑实时处理中的优化需求。
通过采用以上改进,全卷积回归网络结构参数如表1所示。
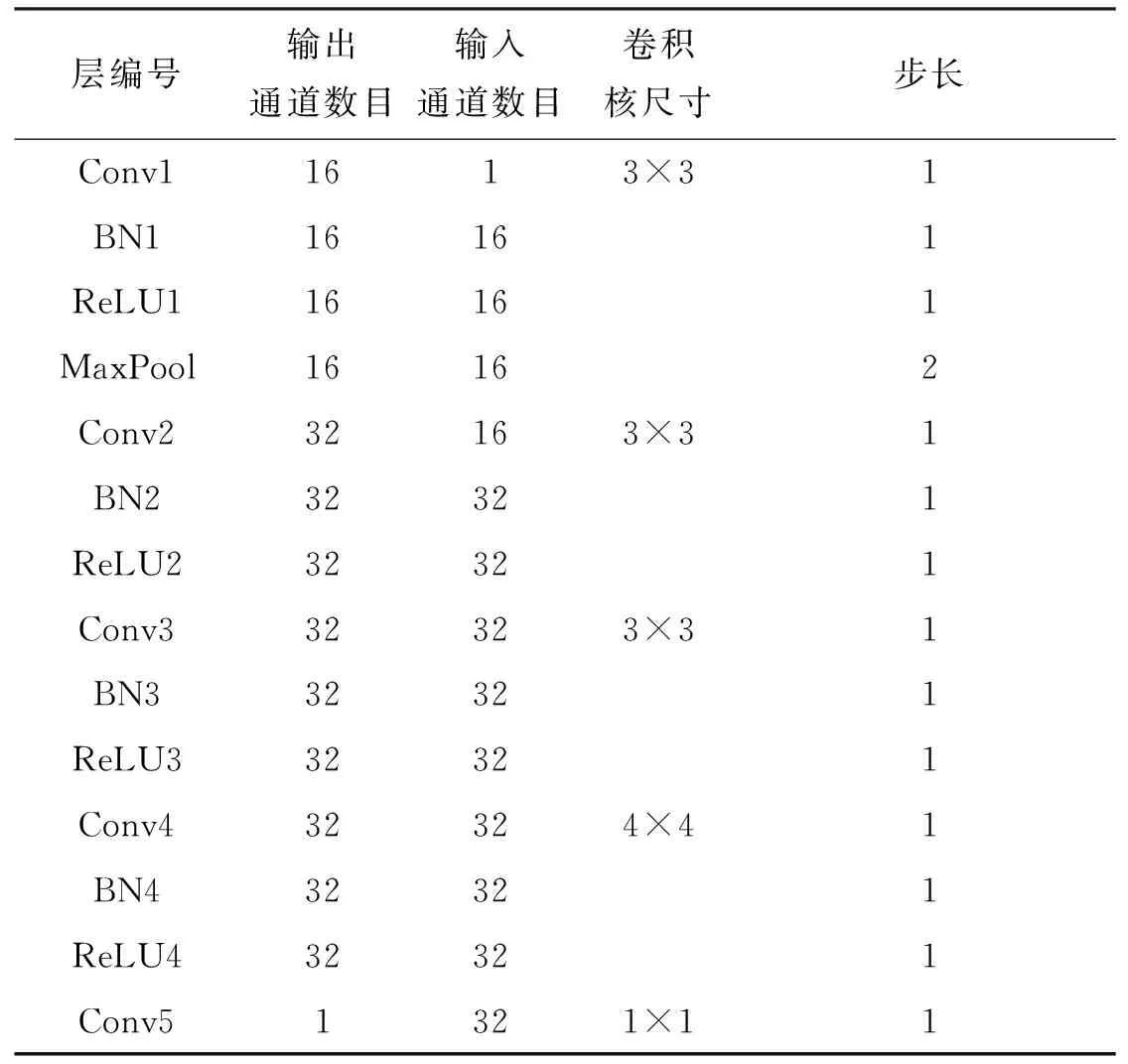
表1 网络参数Tab.1 Network parameter
1.2 轨迹关联
轨迹关联利用目标多维特性进行时序关联性度量,提取高疑似度目标关联序列,抑制虚假目标关联序列的产生,从而实现对目标低虚警率检测。轨迹关联前需将相邻的疑似点连通成一个目标区域,计算目标特性,包括位置、区域大小、能量等,利用这些目标特性度量历史轨迹与当前目标的关联度,实现时域上的轨迹关联。关联过程中未能与历史轨迹相关联的疑似目标均定义为备选起始轨迹供下次关联,各历史轨迹连续多帧不能与新疑似目标关联则判定轨迹消失。关联度量包括:窗口关联度量、能量稳定性关联度量、速度方向一致性关联度量。
1.2.1 窗口关联度量
由于目标运动速度有限,相邻帧间目标的位移也是有限的,因此可以基于历史关联序列位置设置一定大小的关联窗口,对落入窗口内的疑似目标进行关联。关联窗口的设置方式如图3所示,考虑到目标可能会在某一帧发生漏检,若上一帧未关联数据,则将窗口大小适当外扩以保证对受遮蔽目标的间断关联。图3中Δx和Δy为序列末点与待关联疑似点的坐标差,若max(Δx,Δy)小于关联窗口半径,则认为疑似目标满足窗口关联条件。

图3 窗口关联示意Fig.3 Window association diagram
1.2.2 能量稳定性关联度量
同一目标量的能量在相邻帧之间是相对稳定的,可选取轨迹末端点能量峰值Eseq和当前疑似点能量峰值Euc中的最小值作为参考值,如式(1)所示,计算待关联疑似点能量峰值与序列末点能量峰值绝对变化量,其相对参考值的百分比为能量关联度,若该值小于阈值Teng,则认为待关联点满足能量稳定性关联。

(1)
1.2.3 速度一致性关联度量
速度方向一致性判断如图4所示,由于帧间目标运动速度方向在短时间内变化较小,因此基于速度大小和方向一致性可对疑似目标进行关联筛选。

图4 速度方向一致性判断Fig.4 Consistency judgment of speed and direction
具体方法通过计算轨迹方向与目标点方向矢量夹角大小来判断是否满足方向一致性条件,通过计算轨迹速度与目标点速度差值判断是否满足速度一致性条件,并通过阈值进行调整。
本文算法主要面向低空场景小目标红外探测跟踪系统应用,为满足红外探测器高帧频图像处理需求与系统强实时性高稳定性要求,采用现场可编程逻辑门阵列(field programmable gate array, FPGA)进行实现。不同于中央处理器(central processing unit, CPU)、数字信号处理(digital signal processing, DSP)芯片等传统嵌入式处理器,FPGA可以为复杂算法内各处理模块定制单独的硬件处理电路,并针对不同算法模块计算特点优化处理结构,构建低时延并行流水处理架构。本节首先给出算法顶层架构设计分析,继而对算法各模块进行并行化和流水化改进。
2.1 顶层流水架构设计
高帧频红外探测器由于帧周期较短,图像传输时间P往往占据帧周期T的80%以上,因而为实现高帧频图像快速处理,实时输出每帧处理结果,并降低复杂算法各级模块计算与吞吐压力,需要采用图像分块处理思想构建顶层模块间流水处理架构,如图5所示。

图5 算法实现顶层流水架构示意Fig.5 Schematic diagram of algorithm implementation top-level pipeline architecture
图像按行传输等分为M块,在第N块图像传输过程中,可同时进行N-1块图像全卷积推理处理、N-2块图像连通处理和N-3块图像轨迹关联处理。当M取值大于等于3且各处理模块对块图像处理时间小于等于T/M时,可实现各级模块并行流水高利用率实时计算,此时一帧图像处理时延最大值为3T/M,并随着M取值增大显著降低,实现快速目标检测处理。
但M取值过大时也会对块间数据交互与融合带来额外处理压力,本文对尺寸为512像素×512像素的100 Hz红外图像进行处理时取M=16,此时对于单块图像各级模块处理时间应小于0.625 ms。
2.2 全卷积网络优化与实现
采用的全卷积网络在设计中已经充分减少网络层数和模型参数,从而构建轻量化网络。但相对传统算法,全卷积网络计算规模依然较高,因此需进一步优化网络层次、降低计算复杂度,并充分利用FPGA内逻辑资源、DSP硬核资源与片内缓存资源,构建高效并行计算架构,实现全卷积网络算法快速实时处理。
2.2.1 归一化层融合优化
由1.1节可知,算法中全卷积网络主要包含卷积层、池化层与归一化层(BN层)。其中BN层主要在网络训练过程中解决梯度消失和梯度爆炸问题,同时提高泛化性能。BN层的计算公式为:
(2)
式中,xbn为BN层输入,ybn为BN层输出,γ为尺度因子,β为偏移因子,μ和σ2为每个通道的平均值与方差,ε为方差调整因子。BN层计算涉及高精度乘加运算,因而在FPGA实现时需要消耗大量计算时间与参数存储资源,并会显著降低全卷积网络处理时延。同时由于BN层运算与卷积计算模式差别较大,在FPGA实现中很难与卷积计算共享一套处理架构,导致BN层带来较大计算资源开销。
在网络训练结束后,BN层各参数在推理过程中均为静态参数,可通过将BN层参数融入卷积层参数的方法移除BN层计算,显著简化处理流程,具体参数融合方法推导如下。
设卷积计算公式为:
Y=W*X+b
(3)
当卷积层输出为BN层输入时,式(3)可在式(2)中展开。
(4)
此时为省略BN层计算,直接将ybn看成融合后新卷积层输出,则对于新卷积层只需要按照式(5)和式(6)更新卷积层参数即可。
(5)
(6)
由于式(5)和式(6)中所有参数在训练结束后均为静态参数,且精度相同,因此在全卷积网络推理处理前可预先完成参数融合,在保证计算精度的同时直接减除FPGA内原BN层处理资源消耗。融合后网络结构如表2所示。

表2 BN层融合后网络结构Tab.2 Network structure after BN layer fusion
2.2.2 卷积层并行优化
由表2可以看出,经融合优化后的全卷积网络由卷积层、激活层和池化层组成,由于激活层采用ReLU函数,其与池化层在处理上仅需采用简单比较,不涉及复杂乘加运算,复杂度与卷积层卷积运算相差较大,因而对全卷积网络计算优化重点主要聚焦在各卷积层。卷积运算是涉及输入特征图和卷积核权值的三维乘积运算,由4个层次的循环实现,如图6所示。

图6 卷积运算4层循环示意图Fig.6 Four layer loop diagram of convolution operation
从数学角度来看,在对卷积层进行并行优化设计时,可以任意对一个或多个层次循环进行全部或部分展开。但由于展开的大小受限于FPGA片内资源,因而如何选择合适的展开层次与规模是卷积并行优化设计的重点。
算法采用的全卷积网络虽然卷积层数只有5层,但卷积核参数依然高达30 384个,单层输入特征图点数最大为131 072,FPGA片内缓存不足以存储所有数据,需要外部存储器对卷积核参数和层间特征图进行缓存。因此,基于FPGA的全卷积网络实时处理单元由3个层次的存储结构组成:①外部大容量存储器;
②FPGA片内缓存;
③与卷积计算实时处理引擎(processing engine, PE)阵列直接耦合的乘加运算临时寄存器(register, REG)。存储结构如图7所示。

图7 卷积层实时处理存储结构Fig.7 Convolutional layer real-time processing storage structure
每层网络处理时从外部存储器中获取待处理特征图分块和相关卷积核参数到片内缓存,然后按照PE阵列规模将数据转发PE中的寄存器。在PE阵列计算完成后将结果传递回片内缓存,并在必要时存入外部存储器,等待下一层网络计算调用。
为实现全连接网络低时延高效处理,上述处理流程应在PE阵列并行计算的基础上构建细分流水处理架构,即尽可能保证各PE在每个时钟周期内都能执行一次运算。循环并行展开方式的不同直接决定了PE阵列规模和PE数据流模式,继而影响到3个层次存储间数据存储访问模式与片内数据复用机会。
此外,在卷积层优化设计时应充分考虑不同卷积层尺寸的差异,提高PE阵列并行流水处理架构对不同卷积层的匹配性,以最大限度减少由于各卷积层差异带来的计算效率降低。从表2可以看出,网络各卷积层卷积核尺寸差别较大,包含1×1、3×3、4×4三种,因而不适合对卷积核循环进行展开;
输入特征图和输出特征图通道数最小均为1,因此也不适合对输入输出通道进行展开;
全卷积网络结构具有良好的输出特征图尺寸一致性特点,有利于输入特征图循环展开。输入特征图循环并行展开如图8所示。
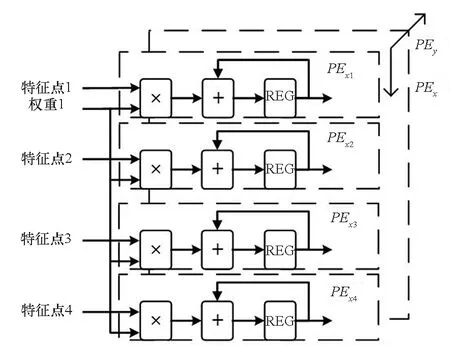
图8 输入特征图并行展开Fig.8 Parallel expansion of input feature map
为最大化PE阵列利用率,应将并行展开变量(PEx,PEy)设置为所有卷积层输入特征图尺寸变量(Ix,Iy)的公因子,由表2可知网络(PEx,PEy)最大可取值为(16,256),但由于每个PE在实现上需消耗FPGA内1个DSP硬核,受限于DSP硬核数量,在实际设计中(PEx,PEy)可取(16,128),此时并行展开度和PE阵列规模为2 048。
2.2.3 全卷积网络计算架构设计
基于BN层融合与卷积并行展开优化设计,图9给出了全卷积网络并行计算架构。架构外围设置了2个动态随机存取存储器(dynamic random access memory, DRAM),分别存储特征图和卷积核。每层卷积处理开始时DRAM在接口管理模块控制下将特征图分块和相应权重分别加载至片内输入特征图缓存与片内权重缓存中,继而依据PE阵列尺寸,通过内部复用数据总线将特征图和权重数据载入各PE,开始高速并行计算。

图9 全卷积网络并行计算架构Fig.9 Full convolution network parallel computing architecture
数据在PE阵列中按输入特征图展开尺度进行每周期不间断并行计算。为尽快得到对应局部输出特征图,降低部分和寄存器数量,便于后端ReLU与池化流水处理,设计时将输出通道循环放在最后一层,先进行卷积核循环与输入通道循环。同时考虑卷积核尺寸较小,为加强PE阵列数据复用降低缓存吞吐压力,设计中先完成卷积核循环输出单通道部分和,继而完成输入通道循环,最后交由多路部分和缓存与累加单元完成数据累加生成。
卷积处理后结果依次传输至偏移累加计算单元、ReLU计算单元和池化处理单元,最终按序存入外部DRAM,等待下一层计算读取。这三层处理由于计算规模较小耗费资源较少,在设计中为尽可能降低处理时延,也按特征图列方向进行了不同尺度的并行化设计。
由于每层运算的参数和尺寸是固定的,因而在存储区中采用少量乒乓缓存技术就可以实现4个卷积循环迭代并行流水和卷积层间的顺序流水计算。所有缓冲区读写地址和PE阵列计算顺序也在编译过程中依据网络模型预先分配并记录,有效降低数据传输额外占用的时间,支撑PE阵列高效并行工作,提高全卷积网络并行计算架构处理性能。
2.3 轨迹关联优化与实现
轨迹关联在设计中为实现低时延处理,重点考虑两个层面的优化加速:一是历史轨迹与多个备选点之间的并行处理,二是单次关联过程中不同维度一致性计算间的并行处理。轨迹关联架构设计如图10所示,轨迹关联主要包括序列与疑似点存取、关联计算和序列更新3个模块。序列与疑似点存取模块完成对已关联序列和待关联疑似点存取;
关联计算模块完成窗口关联、能量一致性关联和速度一致性关联处理;
序列更新模块对关联结果融合判断产生新的序列,并输出存入外部缓存等待下次关联。

图10 轨迹关联架构设计Fig.10 Architecture design of trajectory association
模块采用流水优化方法提高轨迹关联处理速度。理论上处理性能会随流水的级数增加而提高,但同时也会增大对硬件资源特别是片内有限存储资源的消耗。依据模块划分采用三级流水模式,在第二级流水中通过采用多个关联计算单元支撑多备选点与当前轨迹同步并行关联计算,有效降低多备选点的关联处理时间。此外,不同于常规串行关联判断处理方法,对窗口关联、能量一致性关联和速度一致性关联采用独立并行计算后,融合表决判断,进一步大幅度缩短计算时延、提高处理性能。
3.1 实验数据集
实验数据集采用由国防科技大学公开的真实低空场景红外小目标数据集[18],其中包含22个红外序列。序列为地面背景或地面与天空混合背景,包含山、树木、建筑、植被、水等干扰物。为了充分验证本文算法对于复杂场景下红外弱小目标的检测性能,选取了其中场景较复杂的6个序列用于性能测试和分析,其余序列用于构建训练数据集。训练数据集建立过程中除图像中原有目标,还随机添加了不同位置、信噪比和大小的仿真目标对数据集进行了增广,共计13 874幅。表3给出了6个测试序列的细节描述,共计6 649幅红外图像。从目标信噪比范围可以看出场景中的目标为弱目标[19],各个序列的图像复杂程度用序列中各图像场景信噪比(scene signal noise ratio, SSNR)的平均值进行描述,值越大表明场景越复杂,图像SSNR定义如式(7)所示。

表3 测试序列与图像参数Tab.3 Test sequence and image parameters
(7)
式中,M和N分别代表图像长宽,Di,j代表图像中坐标为(i,j)的点邻域方差,Si,j代表坐标为(i,j)的点中心灰度值,Si,j代表坐标为(i,j)的点邻域均值。
3.2 实验与测试平台
实验与测试平台采用课题组自研高性能实时处理机予以验证,检测算法运行在图像处理板上FPGA内,图像处理板实物如图11所示。

图11 自研图像处理板Fig.11 Self-developed image processing board
为验证算法处理性能,以处理机为中心搭建了一套自测试验证系统,系统组成如图12所示。系统采用图像模拟源设备实时高帧频发送测试序列图,由检测结果记录设备实时接收并存储算法各项处理结果,其中包含全连接网络输出的空域检测结果与多帧关联输出的时域检测结果,继而通过结果分析实现对算法功能与性能的测试验证。

图12 自测试验验证系统Fig.12 Self-test verification system
3.3 性能测试与分析
图13按行从上至下分别列出了6个测试序列中的典型场景,并标注出本文所提算法在FPGA处理后获得的检测结果。通过图13(a)可以看出,受大量干扰物影响,人眼几乎很难分辨目标位置。图13(b)和图13(c)为图13(a)相邻两帧经过全卷积网络回归得到的目标概率热图,如红框所示位置,目标在热图中均有很强的响应。但由于场景比较复杂,一些噪声和干扰物也有较强响应。图13(d)为关联后检测结果,可以直观看出,相邻两帧目标概率热图之间存在不同位置的高响应区域,这些响应由随机噪声引起,通过轨迹关联可以有效剔除这一类高响应引起的虚假目标,抑制虚警,最终得到准确的检测结果。
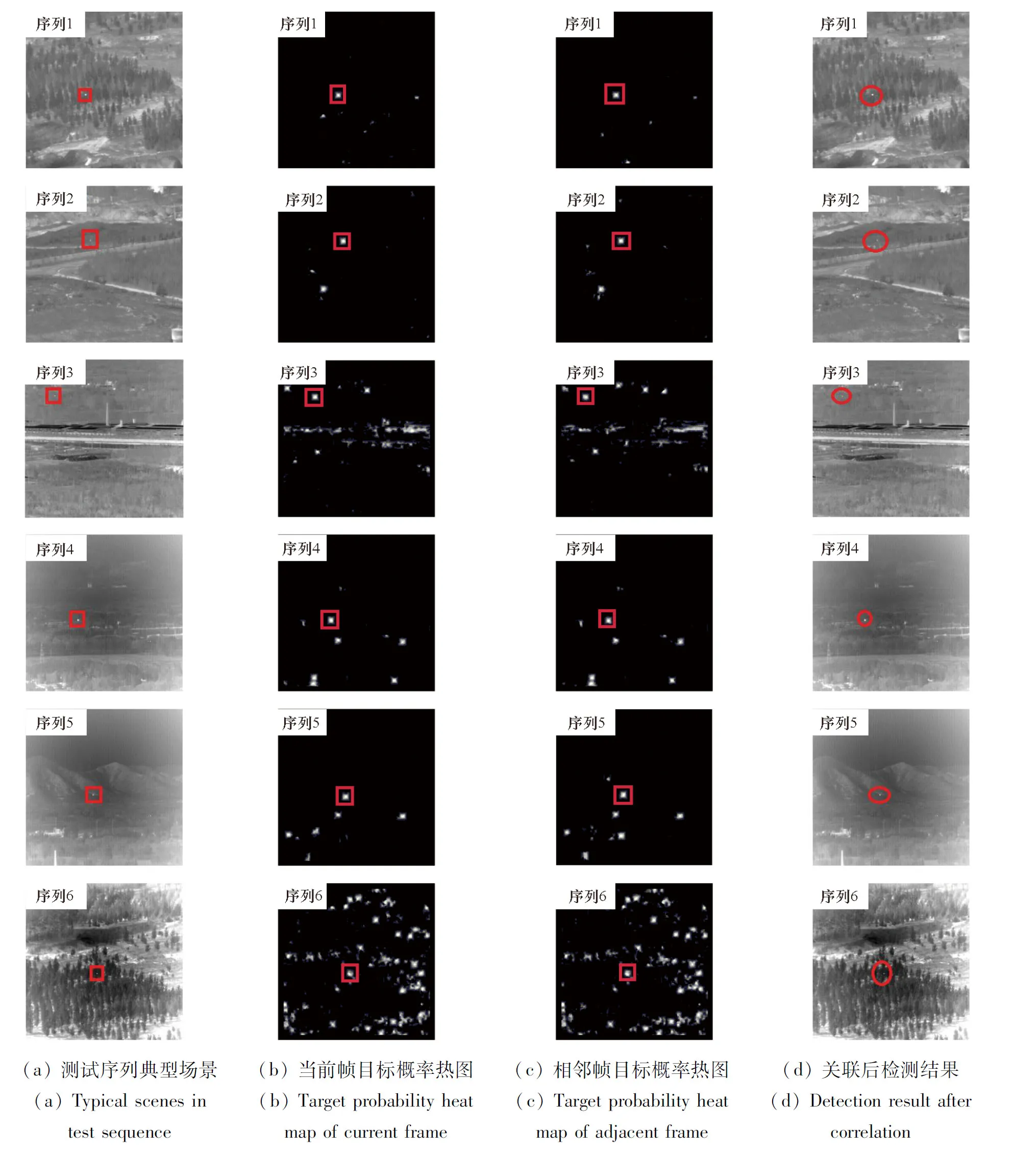
图13 本文算法实现测试结果Fig.13 Algorithm implementation test results of this paper
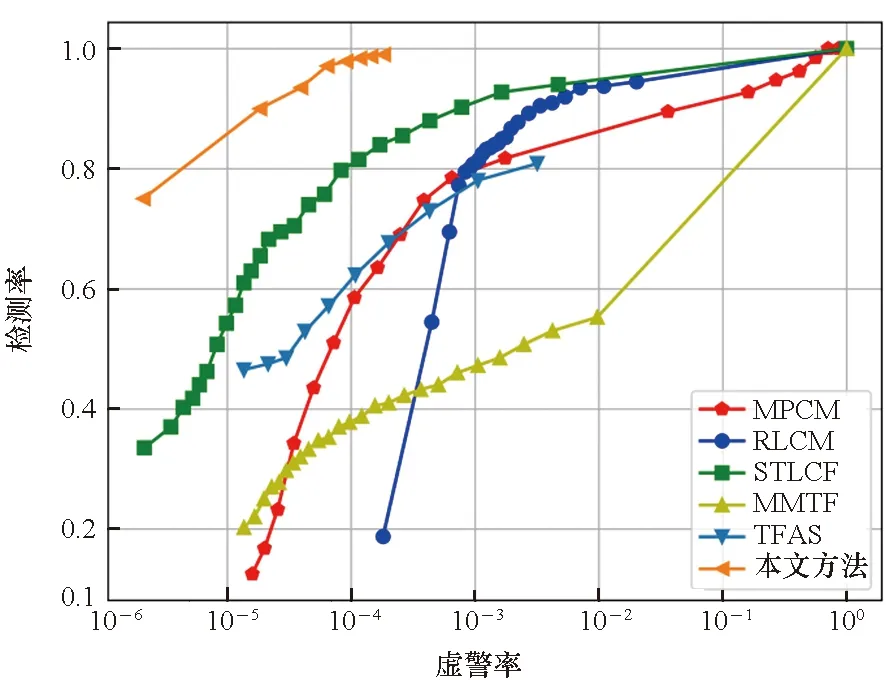
本文方法与其他5个基准方法的接受者操作特性(receiver operating characteristic, ROC)曲线比较如图14所示。其中,通过不同的分割阈值,获得了MPCM、RLCM、STLCF和MMTF 4种基准方法的ROC曲线。TFAS方法的ROC曲线通过不同的位移增量阈值获得。本文方法的ROC曲线同样通过不同的分割与关联阈值获得。与基准方法相比,本文方法在很低的误报率下,能够获得较高的检测率。表4给出了本文方法和其他5种基准方法在6个测试序列下的平均虚警率和平均检测率对比。从中可以看出,本文方法在平均虚警率优于基准方法4倍以上(本文为0.000 1)条件下,平均检测率相比基准方法提高20%以上(本文为93%),并对不同场景具有良好的鲁棒性。

(a) 测试序列1的ROC对比曲线(a) Comparison of ROC curves of test sequence 1

(b) 测试序列2的ROC对比曲线(b) Comparison of ROC curves of test sequence 2

(c) 测试序列3的ROC对比曲线(c) Comparison of ROC curves of test sequence 3

(d) 测试序列4的ROC对比曲线(d) Comparison of ROC curves of test sequence 4
(e) 测试序列5的ROC对比曲线(e) Comparison of ROC curves of test sequence 5
同时表4给出了测试中运行平均速率,其中5个基准方法均在X86平台(CPU为Intel Core I72.0 GHz,内存为16 GB,操作系统为Windows 10)下运行,本文方法分别给出了在X86和FPGA平台下运行的平均速率。可以直观看出经过并行流水优化设计,算法在FPGA平台相对X86平台取得了显著的加速效果,充分满足实时处理应用需求。
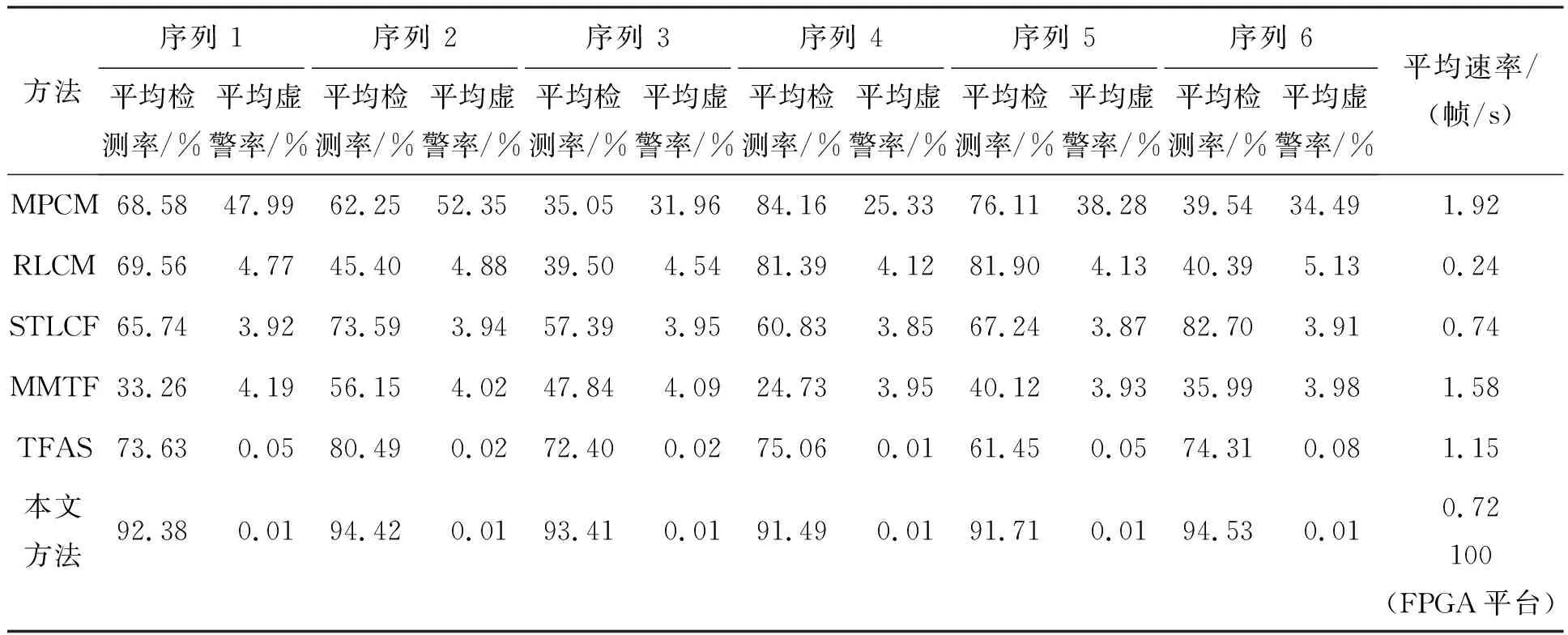
表4 各测试序列中不同方法平均检测率、平均虚警率与平均速率对比Tab.4 Comparison of average detection rate, average false alarm rate and average rate of different methods in test sequence
3.4 FPGA实现资源占用与性能分析
表5给出了优化后的检测算法实现对FPGA资源使用情况,FPGA型号为Xilinx公司产XC7VX690T,开发工具为Vivado 2019.1。如2.2节所述,由于片内块随机存储器(block random access memory, BRAM)和用于实现寄存器功能的触发器(flip flop, FF)需要缓存部分权重、输入和输出部分特征图及大量中间计算结果,BRAM和FF使用率分别高达84%与70%。大量BRAM和FF的使用有效保证了整体并行处理架构无阻塞流水运行,同时缓解了布局布线难度提高系统工作时钟频率。算法中乘法运算全部使用DSP硬核资源实现,由于PE阵列较大使用率达76%。

表5 FPGA资源使用情况Tab.5 FPGA resource utilization
图15给出了FPGA仿真波形,仿真显示单帧图像流水线上各模块最大处理时钟数为1 442 896个时钟周期,FPGA布局布线后给出的最高工作频率为167 MHz,对应最小处理周期为8.64 ms。实际应用时板上时钟为150 MHz,此时最小处理周期为9.62 ms,相对图像帧传输末端时延为1.8 ms,可有效满足100 Hz图像快速实时处理需求。

图15 算法FPGA实现仿真波形Fig.15 Algorithm simulation waveform based on FPGA
针对低空复杂场景下弱小目标检测难题,本文提出一种时空域结合的目标检测方法和基于FPGA平台的实时并行优化处理方法。算法采用轻量化全卷积回归网络进行空域检测,继而对空域检测结果进行连通标记和时域关联获得目标精确检测结果。测试结果表明,在6个复杂低空场景弱小目标测试序列中,本文研究成果在0.000 1虚警率下实现93%平均检测率,较传统方法性能提升显著。并在单片FPGA上完成100 Hz图像实时处理,处理时延低于1.8 ms,性能充分满足对高帧频红外图像中弱小目标快速精准实时检测应用需求。
猜你喜欢关联轨迹卷积不惧于新,不困于形——一道函数“关联”题的剖析与拓展新世纪智能(数学备考)(2021年9期)2021-11-24基于3D-Winograd的快速卷积算法设计及FPGA实现北京航空航天大学学报(2021年9期)2021-11-02轨迹读友·少年文学(清雅版)(2020年4期)2020-08-24轨迹读友·少年文学(清雅版)(2020年3期)2020-07-24“一带一路”递进,关联民生更紧当代陕西(2019年15期)2019-09-02从滤波器理解卷积电子制作(2019年11期)2019-07-04轨迹现代装饰(2018年5期)2018-05-26基于傅里叶域卷积表示的目标跟踪算法北京航空航天大学学报(2018年1期)2018-04-20奇趣搭配学苑创造·A版(2018年11期)2018-02-01进化的轨迹(一)——进化,无尽的适应中国三峡(2017年2期)2017-06-09栏目最新:
- 争做堪当民族复兴重任的时代新人作文9篇2024-05-09
- 志愿者心得体会范文300字5篇2024-05-09
- 社区环境环保活动方案甄选3篇2024-05-09
- 国旗下家风家教学生发言5篇2024-05-09
- 幼儿园食品中毒事件应急预案3篇2024-05-09
- 建功新时代奋进新征程征文作文10篇2024-05-09
- 传统节日中秋节作文范文10篇2024-05-09
- 夏季防溺水安全教育演讲稿范文3篇2024-05-09
- 风险导向视角下医院基建工程内部审计探...2024-05-09
- 万能消防安全教育应急预案4篇2024-05-09