基于深度学习的多通道多任务学习判决预测模型*
郭子晨 李昆阳 娄嘉鹏
北京电子科技学院, 北京市 100070
在我国传统司法领域,裁判文书是由检察院、法官、律师等专业领域人士的专业问题解答和法院审理过程及结果组成。
对于以往的法律判决,法院只能依靠法律条文,按照司法程序人工的处理各类案件。
但随着案件数量的爆炸式增长,司法人员的工作负担大大增加,司法程序周期增加,传统的人工判决已不能满足司法需求。
在1987 年,Gardner 等人[1]初步进行了人工智能与司法决策相互融合的研究,并提出了一系列构建规范预测模型的规则要素。
但由于缺乏大规模标注数据集,初期的研究任务主要是围绕基于知识工程采取手动设计规则的方法展开,用以解决特定场景的法律判决预测任务。
随着机器学习技术的蓬勃发展,为了更好实现法律智能判决,许多学者将罪名预测和文本分类任务结合。
如Liu 等人[2]使用K 近邻算法对罪名进行分类;Katz 等人[3]采用随机树方法预测美国最高法院的审判;Lin 等人[4]提出了聚焦于中文法律文书的机器学习模型;Sulea 等人[5]基于法国最高法院的案件和判决,开发了基于多个支持向量机的预测集成系统。
上述这些基于机器学习的罪名预测方法,任务可分成特征工程和分类器两部分,均存在一定缺陷,主要有以下几点:1)特征工程需要由相关专业人士来设计大量的各领域相关案件特征,工程量庞大而且可移植性较差。
2)这些方法在文本表示上多是采用语义语序缺失的词袋模型和稀疏高维的TFIDF 等方法,均在特征的表达能力上具有一定局限性。
3)各个方法中所使用的训练数据集规模相对偏小,因此遇到文书复杂或数据规模大的情况将难以处理。
近年来,随着神经网络在自然语言处理各任务上取得重大成果。
研究人员也尝试借助神经网络较好的特征抽取能力去提升模型表现,将神经网络应用于罪名预测。
其中,在针对基于案件事实描述进行罪名预测的研究上,邓文超等人[6]使用了多种基于深度学习的文本分类方法对罪名预测任务进行实验;Long 等人[7]将机器阅读理解方法用于解决民事案件的裁判预测问题;He 等人[8]使用序列增强的胶囊网络进行低频罪名的预测;王加伟等人[9]使用层次注意力机制对犯罪事实进行语义差异性建模,并将多标签罪名预测转化为单标签罪名预测问题。
另外,在利用其他辅助信息进行罪名预测的研究中,Luo 等人[10]提出了一个分层的基于注意力的神经网络框架,使用相关法律条文提高罪名预测的准确性;Hu 等人[11]为罪名标记了属性信息,面向低频罪名和易混淆罪名,提出引入区分性属性的罪名预测;Kang 等人[12]从法条的罪名定义中提取有关规范术语作为案件事实描述的辅助信息;Zhong 等人[13]将司法判决预测中罪名预测、法条预测、刑期预测等不同任务之间的相互依赖关系进行建模,形成一个有向无环图(DAG),并提出拓扑学习模型以同时提升子任务性能;Yang 等人[14]在拓扑学习模型的基础上设计了多视角的前向预测和后向验证框架,以增强子任务之间的依赖性。
最后,针对为罪名预测过程提供解释的研究,Ye 等人[15]使用融入罪名标签的Seq2Seq 模型生成具有解释性的法院观点;Jang等人[16]采用深度强化学习方法在案情描述中提取判决依据;Liu 等人[17]将罪名预测建模为一个顺序决策过程,提出的策略控制模型可以在阅读文本过程中的某一时刻做出罪名预测并给出裁判依据,使总文本阅读量减少了30%~40%。
对于法条预测任务,预测模型也随着神经网络的发展不断完善,Luo 等人[18]提出了一种基于注意力机制的神经网络联合学习模型,该模型实现了对罪名及法条预测任务进行联合学习建模;Liu 等人[19]使用文本挖掘方法,实现了为基于日常用语描述的案件寻找相应的法条支持;Liu 等人[20]采用基于实例的分类和内省学习的方法完成法条分类。
综上,目前的法条和罪名预测研究已经取得显著进步,但基于法条和罪名的数据分布极其不平衡,而且数据中存在很多易混淆罪名,这对于模型预测效果提升仍是一项重大挑战。
另外,上述研究大多聚焦于单一任务的处理,而忽略了法条和罪名预测任务间的复杂逻辑关系,这使得罪名预测效果存在准确率瓶颈并缺少法条依据和支持。
因此,结合上述问题,本文针对汉字复杂多义、特征提取粗糙和效率低等问题,构建法条和罪名双通道模型,引入BERT 预训练语言模型,提出一种基于深度学习的多通道多任务学习判决预测模型,主要贡献如下:
1.本文提出并设计了基于多任务学习的罪名及法条预测的整体框架。
整体框架通过双通道实现,首先在法条预测通道中预测法条结果,并将提取的法条结果送入下游结构辅助罪名预测通道进行预测,罪名预测通道通过拼接案情和法条结果综合得出罪名结果。
通过双通道的多任务联合模型,从多个视角捕捉多个维度的特征向量,获取更丰富的语义要素,提升判决模型的预测效果和泛化能力。
其中BERT-BA 模型实现对法条的预测,BERT-BABC 模型联合BERT-BA模型的法条预测结果实现对罪名综合预测。
2.针对法条预测通道,构建了基于BERT 语言预训练模型的法条预测模型BERT-BA,该模型在特征提取层采用BiGRU-Attention 进行特征抽取,通过BiGRU 结构实现长文本上下文语义信息的提取和参数规模的缩减,并基于注意力机制实现关键特征信息的提取。
3.针对罪名预测通道,构建了基于BERT 模型的双通道罪名预测模型BERT-BABC,该模型通过BiGRU-Attention 捕捉案情中的犯罪特征,BERT 特征提取器使用自注意力捕捉内部语义特征作为特征补充,实现了多视角的罪名特征信息提取;同时将法条预测通道的结果与罪名预测通道的结果拼接合并,送入卷积神经网络(Convolutional Neural Networks, CNN)进行深层特征提取,得到罪名分类预测结果,实现了双通道结合判决预测。
4.使用CAIL2018-Small 数据集进行大规模数据训练测试实验,实验结果表明本文的法条预测模型和罪名预测模型得出的法条及罪名预测结果评价指标高于基线模型,提高了判决预测效果和性能。
基于深度学习的判决预测方法主要有两种类型:第一类是基础的预测方法,通过结合不同神经网络针对特定的情境只在案件事实描述的基础上进行建模,来预测罪名及相应的法条;第二类是运用辅助信息的方法,以罪名预测为例,辅助信息包括法律法条、刑期等信息。
这些方法通常是联合训练罪名预测任务和辅助信息相关的任务,可以实现信息共享,进一步丰富所提取的案情特征。
为了增强罪名预测的依据性以及提高罪名判决准确率,本文在案情事实描述建模的基础上联合法条辅助信息,建立双通道模型以从多视角提取不同的案情特征,同时采取BERT 词嵌入方法将训练好的词向量输送至罪名和法条预测任务中,聚焦于优化提升辅助信息模块和神经网络编码器模块,提出了一套基于深度学习的罪名及法条预测多任务学习总体框架,其整体框架流程如图1 所示。
将案情描述分别输入到罪名预测和法条预测模块。
在法条预测模型预测案件相关法条,进而提供支持罪名成立的法条依据,然后输出法条预测结果。
在罪名预测模型,负责接收法条预测相关特征并整合案情描述,经罪名预测模型得到罪名预测结果。

图1 整体框架流程图
1.1 法条预测模型
由于汉字的复杂多义性,案情描述的特征提取及词义表达的准确性会下降,进而影响法条预测模型训练的效果,为了解决这一问题,本文提出了一种基于BERT 和BiGRU 的法条预测模型[21,22],该法条预测模型的结构由输入层、特征抽取层和分类预测层三部分组成,如图2 所示。在法条预测模型中输入案情描述文本,利用BERT 预训练模型,获得包含文本总体信息的动态词向量,接着将新的词向量输入到Bi-GRU 网络进行特征提取,捕捉案情描述的特征信息,最后引入注意力机制,得到输入案情的最终法条预测概率表达,选取概率最高的法条即为法条预测结果。
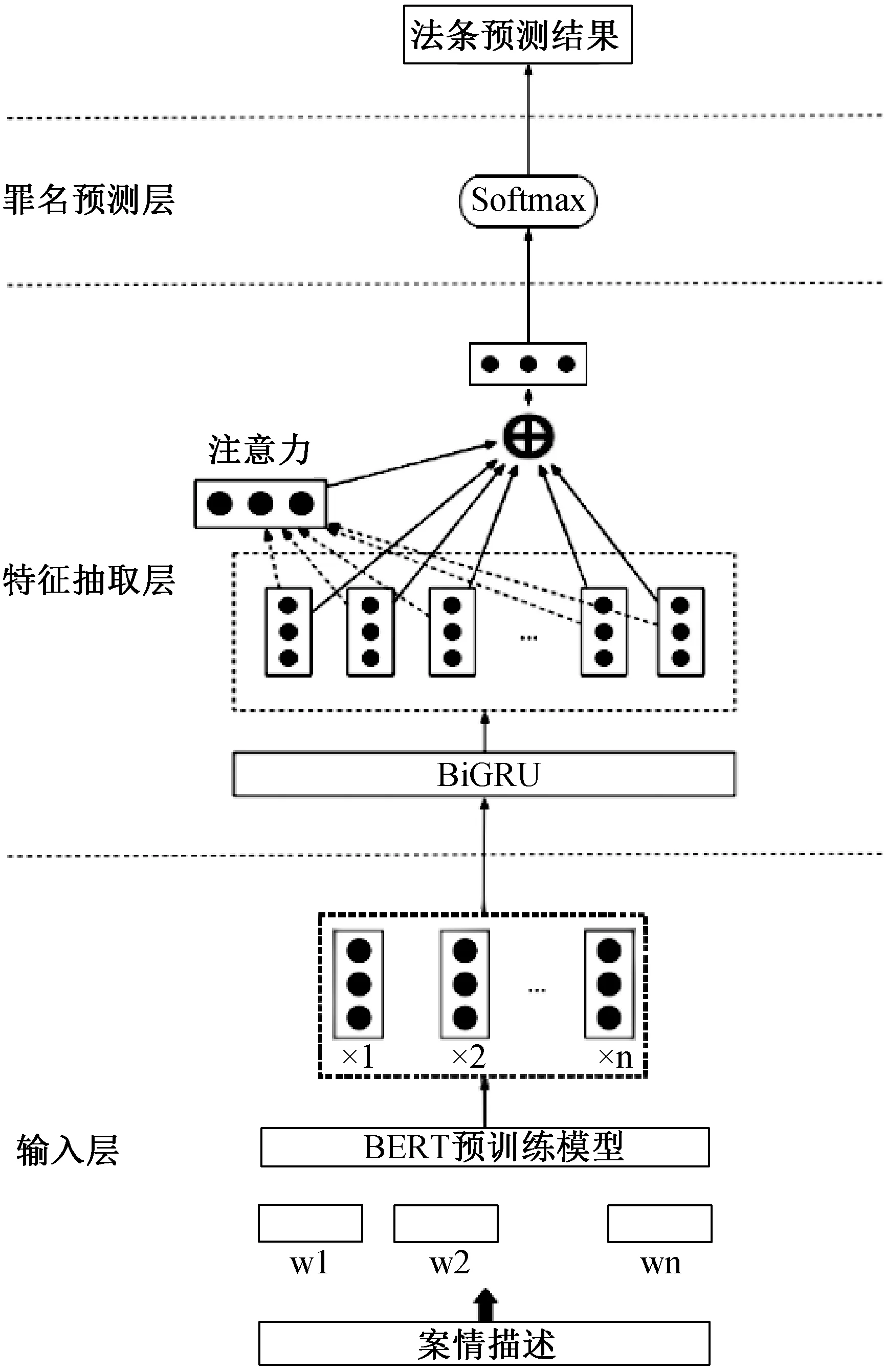
图2 BERT-BA 模型结构
模型的第一层是输入层。
由于汉字的数目量级大和多义复杂,本研究使用BERT 中的WordPiece 嵌入模型进行案情描述,以文本中单个汉字进行词嵌入编码,大大减少了编码规模和案情文本的复杂性。
针对于数据集的统计,超过90%的案情描述文本在300 字以下,因此在词嵌入训练过程中最大序列长度设置为300 个汉字。在输入层中,使用了BERT 预训练语言模型进行了词嵌入,生成了词向量,由于文本描述最大范围为300 个汉字,词向量xi= {x1,x2,…,x300},xi∈Re。
输入到BiGRU 对输入词向量xi进行正向编码和反向编码,编码方式如公式(1)、(2),生成隐藏向量。
后将进行拼接操作生成隐层向量hi, 融合了上文和下文的语义信息,其可看作案情文本的犯罪特征信息的概览。
模型的第二层是特征抽取层。
由于本研究的输入是案情事实文本,属于篇章文本的量级,而且文本描述的犯罪特征存在着较强的依赖关系,为了更准确的把握文本的依赖关系和提升语义的准确性,本文使用BiGRU 模型提取语义特征,并融入注意力机制(Attention)可以更好地关注和提取关键特征信息。
在本研究中,注意力机制实现流程如下:
1. 使用MLP 对Bi-GRU 模型的输出向量hi做非线性变换,得到中间隐含状态ui, 如公式(4)所示;
2. 将ui和上下文权重参数向量uc进行相似度计算,在本文中使用余弦相似度计算,得到文本的注意力得分si,如公式(5)所示;
3. 使用Softmax 函数对注意力得分进行数值转化并归一化,得到注意力权重αi, 如公式(6)所示;
4. 使用文本向量hi与注意力权重αi进行相乘,得到词语的加权向量∈Rd,d为隐层向量维度,如公式(7)所示;
5. 将n个hatti拼接成Satt矩阵,得到最终的文本特征矩阵表示Satt,如公式(8)所示。
模型的第三层是分类预测层。
分类预测层的主要任务是构造分类器,获取案情描述文本相对于法条预测标签的相对得分,输出最终的法条标签结果。
这里使用Softmax 函数对法条标签进行分类,其数学表示如下:
1.2 罪名预测模型
针对传统深度学习模型无法学习到词上下文语义、一词多义以及模型在训练过程中可能存在梯度消失或梯度爆炸的现状,BERT 词嵌入的动态化表示和BiGRU 的循环结构设计很好的解决了这一问题。
本文聚焦于增强案情语义特征抽取能力,使用BERT 预训练语言模型作为词嵌入方法,生成的词编码向量输出至特征提取层的双通道特征提取器进行特征提取。
其中,BiGRU-Attention 用来捕捉案情犯罪特征,BERT特征提取器则通过自注意力机制捕捉内部语义特征作为特征补充,以此来使模型可以获得更多的语义信息。
双通道分别输出各自视角的特征向量,并将二者生成的词向量与法条预测模型的法条特征向量进行向量拼接,接着将拼接的文本向量送入下游的CNN 模型进行文本的深层次特征提取和分类,最后得出罪名的预测结果。
其罪名预测模型的结构如图3 所示。

图3 BERT-BABC 模型结构
模型的第二层是特征抽取层[23]。
在特征抽取层,BERT-BABC 使用了双通道模式:BiGRUAttention 作为主特征提取通道,用于捕捉案情描述文书中的犯罪特征;BERT 作为补充特征提取器,使用自注意力机制捕捉内部案情语义特征。
模型的第三层是语义连接层。
语义连接层的主要作用是连接双通道任务的输出向量,即连接罪名预测通道的输出向量和法条预测通道的输出向量。
为简化模型计算量,采用行连接的方式进行向量信息特征融合。
具体来说,即连接罪名预测通道中BiGRU-Attention 特征提取器的输出、BERT 特征提取器的输出和法条预测通道中BiGRU-Attention 特征提取器的输出,并构建案情描述文本的整体语义信息向量,如公式(10)所示。
其中S 是整体语义信息向量,Sa代表法条预测通道的BiGRU-Attention 模型输出的语义信息向量,Sc1代表罪名预测通道中BiGRUAttention 主特征提取器输出的语义信息向量,Sc2代表罪名预测通道中BERT 辅助特征提取器输出的语义信息向量。ra、rc1、rc2分别是Sa、Sc1、Sc2向量的行数,c是Sa、Sc1、Sc2向量的列数。
模型的第四层深度提取层。
深度提取层的主要功能是进行局部深度特征提取:在进行多个向量拼接后为防止特征信息混杂,本文采用CNN 对拼接特征向量进行局部的关键特征信息提取,主要由卷积、池化和预测三组成。
1.卷积模块。
对语义连接层的输出矩阵S进行卷积操作,假设卷积核的大小为w, 即一次卷积对w个相邻词向量进行操作,以获取文本的局部关键特征信息,特征的提取表达如(11)所示:
对输出矩阵S的每一个词向量进行卷积后,得到文本特征映射y= [y1,y2,…,yn-w+1]。
2.池化模块。
对y 进行最大池化操作,用于进一步减少模型参数和向量维度,防止过拟合现象。
如公式(12)所示。
其中,T是池化步长,R是池化窗口大小。
3.预测模块。
对CNN 层的输出向量进行拼接得到最终的向量,输入到分类器中进行分类,得到罪名的预测结果。
语义连接层的输出向量经过CNN 层之后,增强了局部的特征信息,将这些特征信息拼接后进行罪名预测,提高了模型的识别准确率。
2.1 实验环境
本文的实验环境为Ubuntu16.04 操作系统,Intel Core i7 处理器,NVIDIA RTX2070 显卡,2TB 硬盘,32GB 内存,开发语言为Python3.6,深度学习框架选择Pytorch。
2.2 实验数据集
本研究采用2018 年中国“法研杯”司法人工智能挑战赛的公开中文数据集CAIL2018[24],该数据集是首个大规模应用于中文法律判决预测的数据集,共包括2676075 刑法法律文书,共涉及183 条罪名,202 条法条,由CAIL2018-Small 和CAIL2018-Large 两组数据集和一组测试集CAIL2018-Large-test 组成,其中Small 包含19.6 万条法律文书,Large 包含150 万条法律文书,其数据全部来自中国裁判文书网上的真实刑事法律文书,标准答案是案件的判决结果。
数据集的详细分布情况如表1 所示。

表1 CAIL2018 数据集分布
2.3 法条预测实验
为验证法条预测模型的有效性,分别设计两组对比实验:第一组在输入层设置对比,使用不同的词嵌入方法,连接BiGRU-Attention 进行学习训练,来验证BERT 词嵌入的有效性;第二组在特征抽取层设置对比,使用BERT 词嵌入方法,连接不同的神经网络模型进行特征提取,来验证BiGRU-Attention 的有效性。
参数设置如表2 所示。

表2 模型通用参数设置
(1) 输入层对比实验
不同输入层的法条预测实验结果如表3 所示,由实验可知,基于BERT 预训练语言模型的法条预测模型在微平均Fmicro和宏平均Fmacro上均取得最优的效果。
ELMo 和BERT 预训练语言模型均为动态模型,二者的得分S均全面高于基于Word2Vec 和GloVe 结构的模型。
相比ELMo模型的LSTM 结构,BERT 模型采用了特征提取能力更强的Transformer 结构,并且在大规模专业刑事文书数据上进行了预训练,微平均Fmicro和宏平均Fmacro均相较ELMo 提升2.22%和2.06%,得分S提升2.14,效果提升显著。
综上,使用BERT 预训练语言模型作为本法条预测模型的输入层结构有着极为出色的效果。
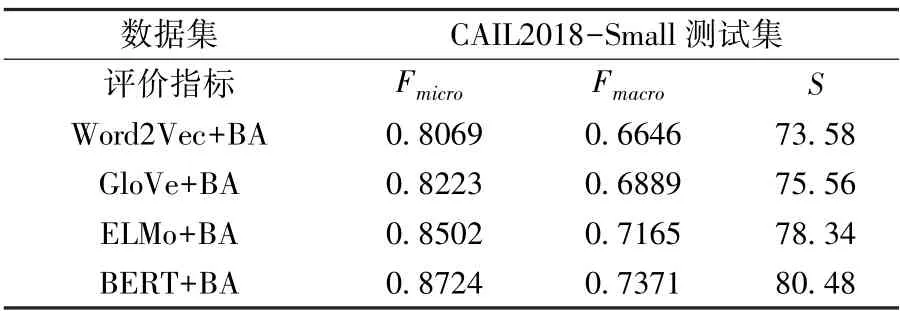
表3 不同输入层的法条预测结果
(2) 特征抽取层对比实验
不同特征抽取层的法条预测结果如表4 所示。
根据上表得出,BiGRU-Attention 结构在微平均Fmicro和得分S均取得最优效果。
对比BA结构和CNN 网络,由于CNN 对于局部特征的抽取能力上更强,在本数据集上,CNN 结构的预测结果宏平均Fmacro略高于BA 结构;对比BA 结构和LSTM 网络,BA 结构中加入了双向信息传递和注意力机制,增强了局部特征提取能力,BA结构在所有指标上均高于LSTM 网络;对比BA和BiGRU 结构,由于加入了注意力机制,BA 结构更有助于提取文本的重点特征信息,在微平均Fmicro和宏平均Fmacro均相较BiGRU 提升3.69%和3.02%,得分S提升3.36,效果提升显著。
综上,使用BA 模型作为作为本法条预测模型的特征抽取层结构有着显著优势。
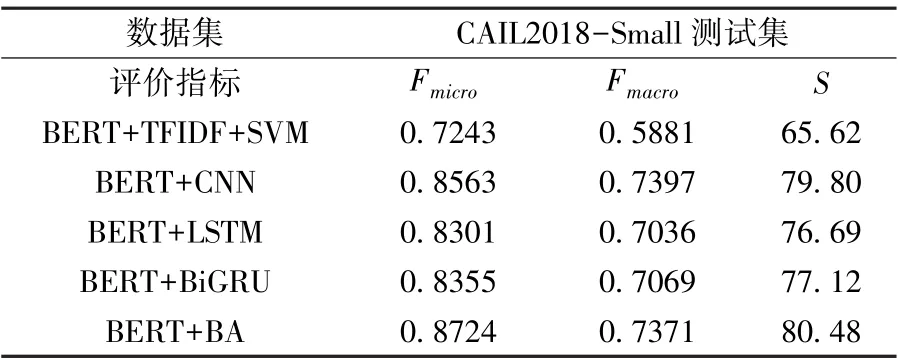
表4 不同特征抽取层的法条预测结果
2.4 罪名预测实验
参数设置如表5 所示。

表5 模型通用参数设置
对常用特征提取基线模型进行比对实验,实验结果如表6 所示。
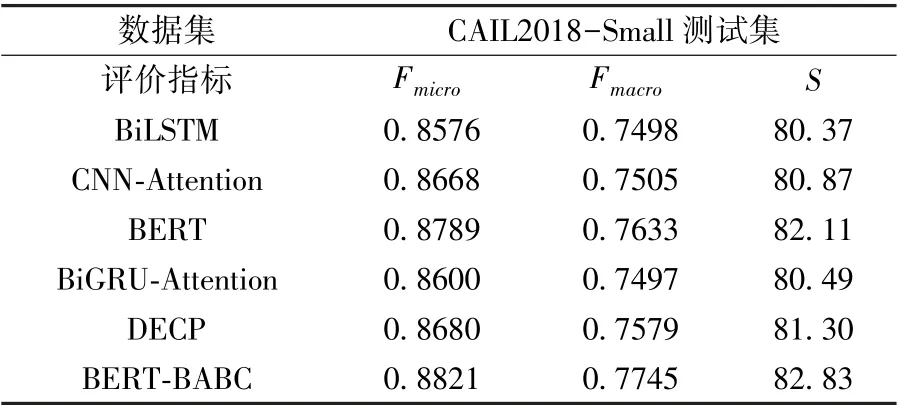
表6 不同特征提取器的罪名预测结果
根据上表的对比实验结果得出,BERTBABC 模型在微平均Fmicro、宏平均Fmacro和得分S均取得最优效果。
对比BiLSTM、CNN-Attention和DECP,CNN 在局部特征抽取上有着出色的表现,并且融入Attention 机制使得CNN 更能关注到重点特征,BiLSTM 在长距离依赖和梯度消失的优越性未在此训练集上显示出来,而融合了CNN 和BiLSTM 各种优势的DECP 模型在此测试集中表现较好;对比BERT-BABC 和前面三个模型,BERT-BABC 做到了融合RNN、CNN 和拥有自注意力机制的BERT 模型的优势,在此预测任务上有着出色表现;对比单一的BERT、单一的BiGRU-Attention 和BERT-BABC,双通道的BERT-BABC 在效果上均优于其中任一单一通道模型,在微平均Fmicro、宏平均Fmacro两项指标上分别比单BERT 高出0.32%、 1.12%, 比单BiGRU-Attention 高出2.21%、2.48%,得分S分别高出0.72、2.34,效果出色。
综上,使用BERT和BiGRU-Attention 双通道特征抽取模型作为本罪名预测模型的信息提取层结构有着极佳的效果。
本文使用2018 年中国“法研杯”司法人工智能挑战赛的公开中文数据集CAIL2018,采用深度学习方法对罪名及法条预测展开分析与设计建模,旨在完成更好的法条和罪名决策。
针对目前模型决策准确率存在瓶颈、神经网络编码视角单一等问题,从犯罪案情描述特征、内部语义特征和法条辅助信息这三个角度进行编码建模,提出了一种基于深度学习的多通道多任务学习判决预测模型,而且罪名的判决是基于法条的,考虑了两个任务的相关性。
结果发现,本文方法在决策效果上取得较好的成绩。
但因为本研究针对的是单人单罪的案件,在现实世界中还存在着多主体犯罪的案件,且多主体犯罪案件缺少数据集。
因此未来可以在多主体犯罪场景的司法文书数据集的构建以及判决预测模型方案的设计上进一步展开探索。
猜你喜欢法条案情罪名凌晨“案情”南方周末(2020-01-30)2020-01-30是谁下的毒青少年科技博览(中学版)(2019年12期)2019-04-10旺角暴乱,两人被判暴动罪环球时报(2018-05-19)2018-05-19从法条的公司法到实践的公司法职工法律天地·下半月(2017年10期)2017-09-23从法条的公司法到实践的公司法进出口经理人(2017年8期)2017-09-13论民法对人身权的保护法制与社会(2016年32期)2016-12-01刑法罪名群论纲*浙江警察学院学报(2016年5期)2016-08-15从法条的公司法到实践的公司法商(2016年20期)2016-07-04重新认识滥用职权和玩忽职守的关系*——兼论《刑法》第397条的结构与罪名刑法论丛(2016年2期)2016-06-01减少死刑的立法路线图中国检察官(2015年19期)2015-01-30栏目最新:
- 物理学习总结高中8篇【优秀范文】2024-04-28
- 高一学习自我总结7篇【精选推荐】2024-04-28
- 2023年度学习知识点初三8篇(完整)2024-04-22
- 2023学习高中数学总结7篇【完整版】2024-04-20
- 英语口语基础学习2024-04-20
- 培训学习总结汇报8篇2024-04-15
- 2023年度学习计划表初中16篇【优秀范文】2024-04-10
- 小学语文主题学习12篇2024-04-07
- 青年大学习“第15期”详细答案()2024-03-19
- 飞行专业学生通识英语的学习2024-03-13